Bloom Filter - Torne sua busca mais rápida e eficiente com este algoritimo
Entenda como melhorar a performance de consultas com bloom filter
O Problema
Você desenvolveu uma aplicação em três camadas (frontend, backend e banco de dados) cuja principal funcionalidade é cadastrar clientes. Como parte desse processo, uma das validações verifica se o e-mail informado já existe na base de dados, evitando duplicações.
No início, tudo funciona bem. A aplicação suporta um número razoável de clientes, e as consultas ao banco para validar e-mails não impactam a performance.
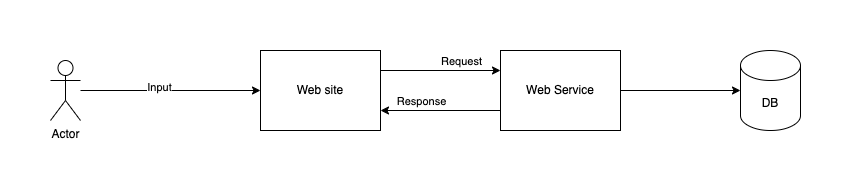 Representacao da arquitetura da aplicacao em 3 camadas
Representacao da arquitetura da aplicacao em 3 camadas
O tempo passa, a empresa cresce e começa a atender um número muito maior de clientes. Com esse aumento, surgem problemas de desempenho. Você analisa os gargalos e descobre que as idas constantes ao banco de dados apenas para verificar a existência de e-mails estão degradando a performance da aplicação.
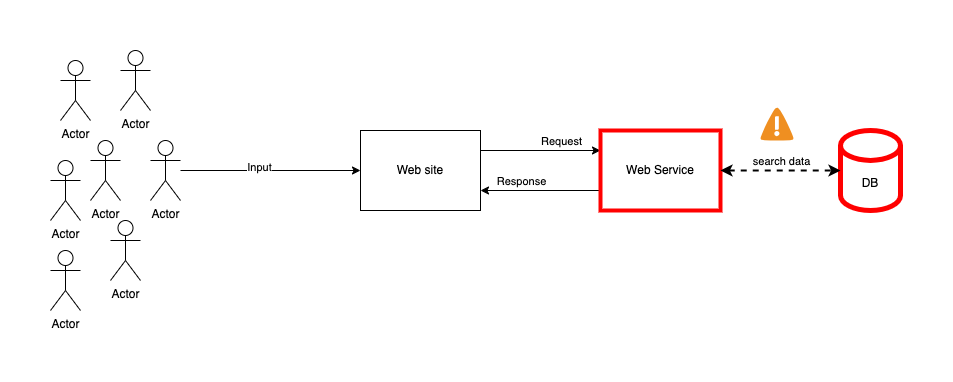
A primeira ideia que vem à mente? Cache!
Cache é a solução?
De fato, ao armazenar e-mails já consultados em um cache (como Redis ou Memcached), a aplicação evitaria diversas idas ao banco. Porém, pense comigo: vale a pena usar cache apenas para armazenar um booleano (true ou false) sobre a existência de um e-mail?
Se você utilizar um cache tradicional, ele exigirá espaço proporcional à quantidade de registros armazenados. Para milhões de e-mails, o custo de memória pode ser considerável.
Agora, e se eu te dissesse que existe uma solução extremamente eficiente, capaz de armazenar 1 milhão de registros em apenas 1 MB de memória (com base na calculadora de bloom filter), fornecendo uma resposta rápida sobre a existência de um dado?
Bem-vindo ao Bloom Filter!
O que é Bloom Filter?
O Bloom Filter é uma estrutura de dados probabilística que permite testar a pertinência de um item em um conjunto de forma muito eficiente em termos de espaço e tempo.
A principal característica do Bloom Filter é que ele pode retornar falsos positivos, mas nunca retorna um falso negativo. Ou seja, se ele diz que um e-mail não existe, então realmente não existe. Mas, se ele diz que o e-mail existe, pode haver uma pequena chance de erro.
Isso o torna perfeito para casos onde queremos evitar consultas desnecessárias a um banco de dados, garantindo que só realizamos buscas quando há alta probabilidade de um item estar presente.
Como o Bloom Filter ajudaria no nosso cenário?
No nosso caso de validação de e-mails, a aplicação poderia seguir a seguinte estratégia:
- O usuário digita um e-mail no cadastro.
- A aplicação consulta o Bloom Filter para verificar se esse e-mail já foi cadastrado.
- Se o Bloom Filter disser que o e-mail não existe, temos certeza absoluta disso e podemos prosseguir com o cadastro.
- Se o Bloom Filter disser que o e-mail pode existir, fazemos uma consulta real no banco de dados para confirmar.
Com essa abordagem, eliminamos a maioria das consultas desnecessárias ao banco, melhorando o desempenho e reduzindo custos.
Por que Bloom Filter é melhor que cache nesse cenário?
| Característica | Cache Tradicional | Bloom Filter |
|---|---|---|
| Armazena dados exatos? | Sim | Não (possibilidade de falso positivo) |
| Consumo de memória | Alto | Extremamente baixo |
| Tempo de consulta | Rápido | Instantâneo |
| Evita 100% das consultas? | Não (pode precisar consultar o banco) | Não (mas reduz drasticamente as consultas) |
Se o objetivo fosse armazenar o próprio e-mail e não apenas sua existência, o cache ainda seria necessário. Mas, quando queremos apenas um filtro rápido e leve, o Bloom Filter é muito mais eficiente!
Quando usar Bloom Filter?
O Bloom Filter é ideal para cenários onde:
- Precisamos verificar rapidamente se um item pode existir antes de buscar no banco.
- Queremos reduzir o número de consultas caras a um banco de dados.
- O espaço em memória é limitado e não queremos armazenar o conjunto completo de dados.
Ao enfrentar problemas de performance causados por consultas repetitivas ao banco, a primeira solução pode parecer ser um cache. No entanto, para problemas de existência de dados, o Bloom Filter é uma alternativa extremamente eficiente e econômica.
Ele reduz drasticamente as consultas ao banco, consome pouca memória e melhora o desempenho geral da aplicação.
Embora esse algoritmo possa parecer simples e pouco relevante à primeira vista, não se engane! Ele é amplamente utilizado em casos críticos e de alto desempenho, como na filtragem de consultas DNS, onde ajuda a bloquear domínios maliciosos antes que os servidores externos sejam acessados.
Show me the code
Veja um exemplo simples da implementacao deste algoritimo no meu github